
1. The Real Cost of Blind Spots

When the mission’s on the line, there’s no such thing as “minor downtime.”
Imagine this: A critical healthcare application goes dark for five minutes during peak usage. No alerts fired. No one noticed—until patients started calling. Now there’s a help desk fire drill, engineers scrambling through logs, and leadership breathing down everyone’s neck.
Sound familiar? That’s the cost of a visibility gap.
At Colossal, we’ve seen firsthand how blind spots in application performance or infrastructure telemetry can cascade into real-world mission failures. And in the federal space, those failures aren’t just annoying—they’re unacceptable. Whether it’s veterans waiting for benefits to process, or warfighters depending on intel feeds, every second counts. Every signal matters.
Here’s the kicker: Most of these failures are preventable. But only if you can see them coming.
Modern systems are complex beasts—hybrid, containerized, and scattered across clouds, data centers, and DMZs. Trying to manage them with legacy tools or patchwork logging is like flying a fighter jet with duct-taped gauges. You might make it through, but at some point, something’s going to break—and you won’t know where, why, or how fast it’s spreading.
That’s where observability comes in. And not just logs and dashboards, but real-time, full-stack, signal-rich observability that gives your engineers superpowers.
Because in a world where uptime is mission-critical, you don’t just need to monitor—you need to understand.
2. Why Observability is Not Just Logging Anymore
Let’s clear something up: observability isn’t just a fancy word for logging.
If your monitoring strategy still revolves around stitching together log files and praying grep gives you answers, you’re not doing observability—you’re doing archaeology.
In today’s world of containerized microservices, ephemeral infrastructure, and CI/CD pipelines moving faster than most change boards can blink, traditional monitoring falls flat. It shows you when something’s broken—usually after someone else already told you. Observability? That’s what tells you why it broke, how it’s behaving right now, and what’s about to break next.
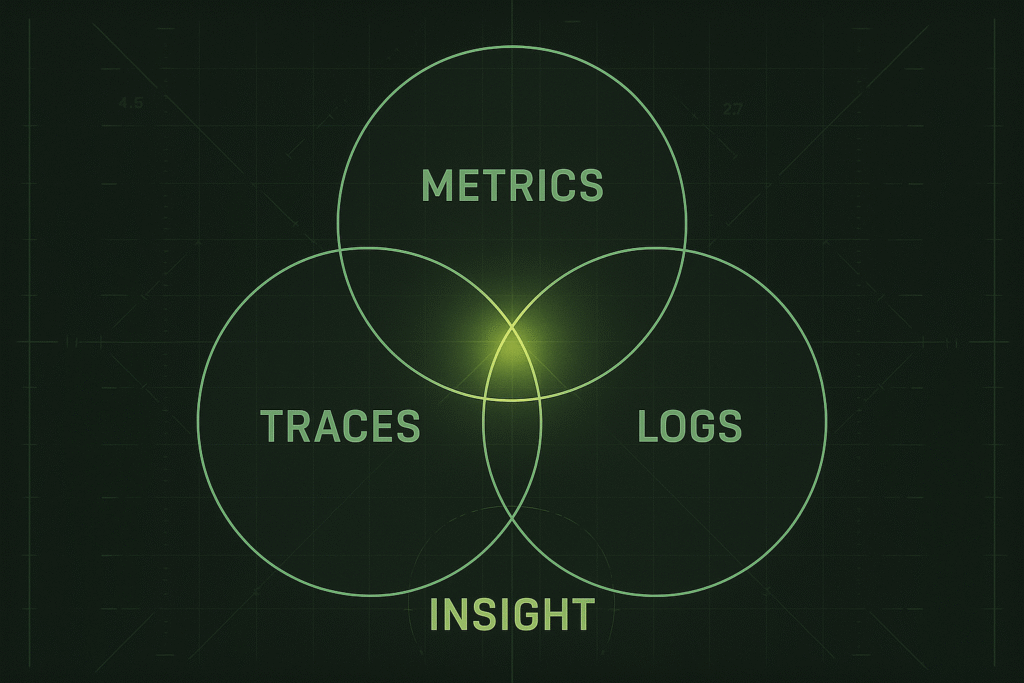
True observability brings together:
- Metrics: What’s the system doing?
- Traces: Where did that request go?
- Logs: What happened when it failed?
Put them together, and you’ve got context, not just chaos.
Observability isn’t about collecting more data—it’s about connecting the right data across your stack. App to infra. API to backend. Network to user session.
And in federal environments, where performance, compliance, and security all matter deeply, this kind of clarity isn’t optional—it’s essential.
Monitoring tells you the lights are off. Observability tells you who kicked the cord, how hard, and what’s catching fire next.
3. Enter Splunk Observability Cloud

Splunk doesn’t just collect data. It connects the dots.
With real-time streaming telemetry, full-fidelity distributed tracing, AI-driven alerting, and dynamic dashboards, Splunk Observability gives your engineers the tools to move from “what just happened?” to “we fixed it before anyone noticed.”
Here’s why we deploy Splunk Observability at Colossal:
- Full-stack visibility – From the browser to the pod to the packet
- High-cardinality metrics at scale – No sampling. No blind spots.
- Plug-and-play integrations – AWS, GCP, Azure, Cisco—you name it.
- AI-powered insights – Not just alerts, but actual answers.
Now combine that with Colossal’s certified Splunk and Cisco engineers, and you’ve got more than a dashboard. You’ve got a tactical edge.
Whether you’re running IL6 workloads, edge computing platforms, or hybrid apps that span mission systems and cloud zones, Splunk gives us the visibility—and Colossal gives you the expertise—to keep your operations running at mission speed.
4. The Colossal Advantage
Let’s be real: tools don’t solve problems—engineers do.
At Colossal, observability isn’t a service add-on. It’s a discipline. We’ve built a team of engineers who specialize in building resilient, always-on systems that operate in some of the most demanding environments on Earth.

- 🎯 Tailored Architectures – No cookie-cutter dashboards. Everything we build is purpose-fit for your mission.
- 🤝 Cisco + Splunk Certified – Our engineers bridge the gap between infrastructure and application, and we use both ecosystems to extract the most useful telemetry.
- 🛡️ Built for Compliance and Security – FedRAMP High, IL6, CMMC? We operate there every day.
- ⚙️ End-to-End Expertise – From the first line of telemetry to the last automated recovery script, we don’t leave gaps.
We don’t just monitor systems—we give them situational awareness.
And when something goes wrong (because something always goes wrong), our systems and people are already ahead of it.
5. What “Always-On” Really Takes
Everyone loves to say their app is “mission-critical.” But when push comes to shove—when a dependency breaks, a region fails, or that 2 a.m. deploy goes sideways—only the observant survive.

At Colossal, we engineer for resilience first. Always-on means always prepared.
Our playbook includes:
- 🔁 Proactive monitoring
- 🚨 Meaningful alerting
- 🧠 Human + AI analysis
- 🧰 Automated remediations
- 🔒 Built-in compliance
We bake observability into:
- CI/CD pipelines
- Infrastructure as Code
- Runbooks and incident response
- Postmortems and improvement cycles
This isn’t about five nines on a sales sheet. It’s about mission continuity, lives saved, intelligence delivered, and downtime prevented.
Resilience isn’t luck. It’s engineered. And we help you build it.
6. Let’s Make It Happen
At Colossal, we don’t just “do” observability—we engineer it for the mission.
We understand that your systems can’t afford guesswork. Your users can’t afford lag. And your mission can’t afford downtime. That’s why we’ve built an observability practice rooted in expertise, driven by data, and obsessed with outcomes.
Whether you’re operating in a zero-trust environment, running hybrid workloads across secure enclaves, or modernizing legacy systems under compliance pressure—we’ve got you. Our team of certified engineers knows how to architect solutions that deliver clarity, continuity, and confidence when it matters most.
And when it comes to visibility, our approach is simple:
See everything. Miss nothing. Move at mission speed.
Let’s build something resilient together.
🚀 Ready to see what observability looks like in action?
Reach out to Colossal today. Our engineers are ready to help you eliminate blind spots, reduce downtime, and bring mission assurance into full view.
🔗 www.colossal-llc.com











