
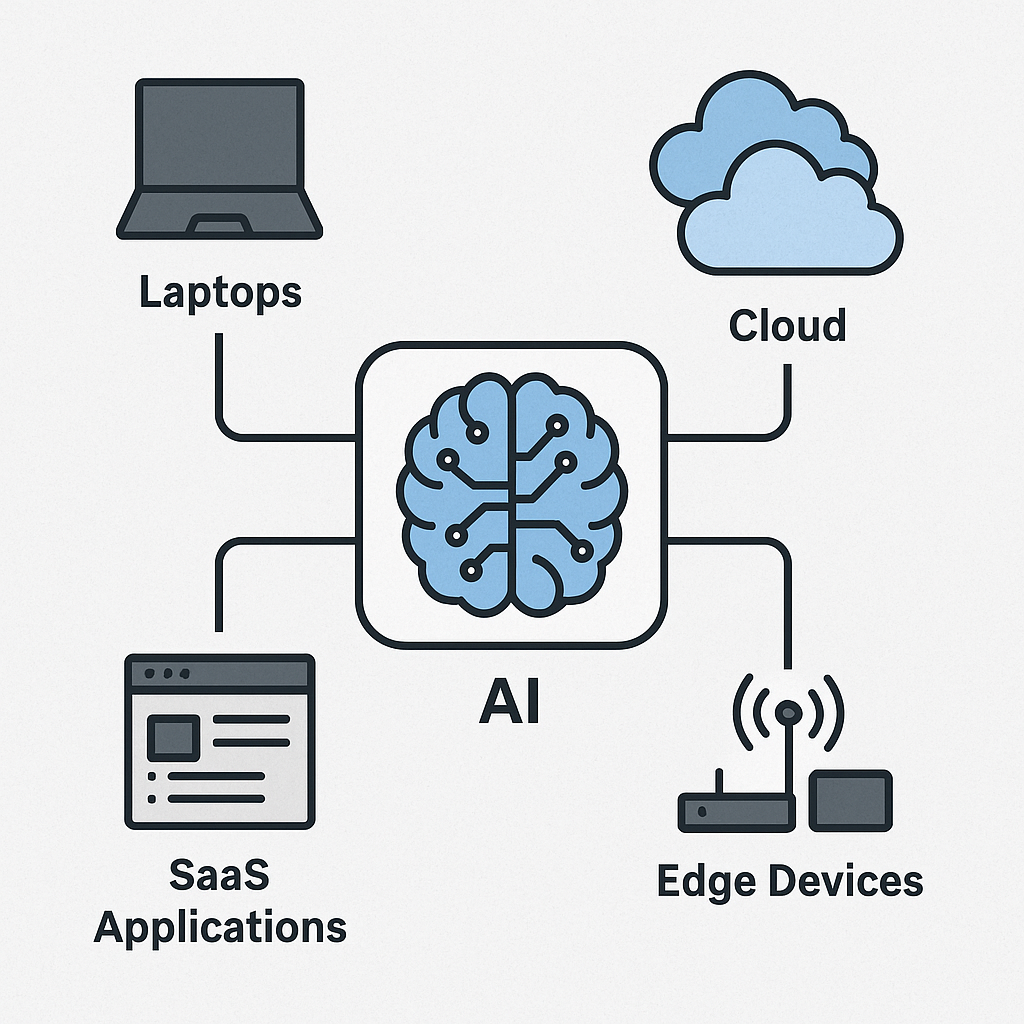
Let’s be real: Data used to be easy.
There was a server room. Maybe a NAS. A few spreadsheets shared on a network drive, and a database that lived on a box in the corner labeled “Do Not Touch.”
Now? Your enterprise data is spread out like confetti at a ticker-tape parade.
It’s:
- On employee laptops
- In Google Drive, OneDrive, Dropbox, and some mystery file named “final_v3_REALLYFINAL.docx”
- Locked away in SaaS apps with no export button
- Sitting in AWS S3 buckets, Azure Blob storage, and that one old SQL server no one wants to admit still exists
- Streaming in real time from IoT sensors, mobile devices, and edge systems
Welcome to the age of data sprawl.
And with sprawl comes risk, inefficiency, and maybe worst of all—missed opportunity. Because hiding in that messy jungle of data is the insight that could help your team move faster, protect more, or even save lives.
So how do you actually wrangle it all?
Let’s break it down.
Why Wrangling Enterprise Data Actually Matters
We’ve all heard the saying: “Data is the new oil.” But that’s only half true.
Crude oil isn’t useful until it’s refined. And data? Same deal. Raw, unstructured, and fragmented data isn’t helping anyone make good decisions. In fact, it’s usually doing the opposite—slowing things down, increasing risk, and making your AI models cranky.
A solid data strategy today needs to do three things:
- Protect the data — because zero trust isn’t optional anymore
- Unify the data — across silos, clouds, and environments
- Make it useful to AI — without copying it all to one massive lake
Now let’s talk about how you actually do that.
1. Start with Zero Trust Data Access
Gone are the days where a strong firewall and a locked server room meant “we’re good.”
Today’s security landscape demands a Zero Trust approach, especially when it comes to data.
Zero Trust means:
- Assume every request is untrusted—until proven otherwise.
- Authenticate users and devices and applications.
- Apply least privilege access—no more “everyone gets full access to the shared drive because it’s easier that way.”
- Audit everything.
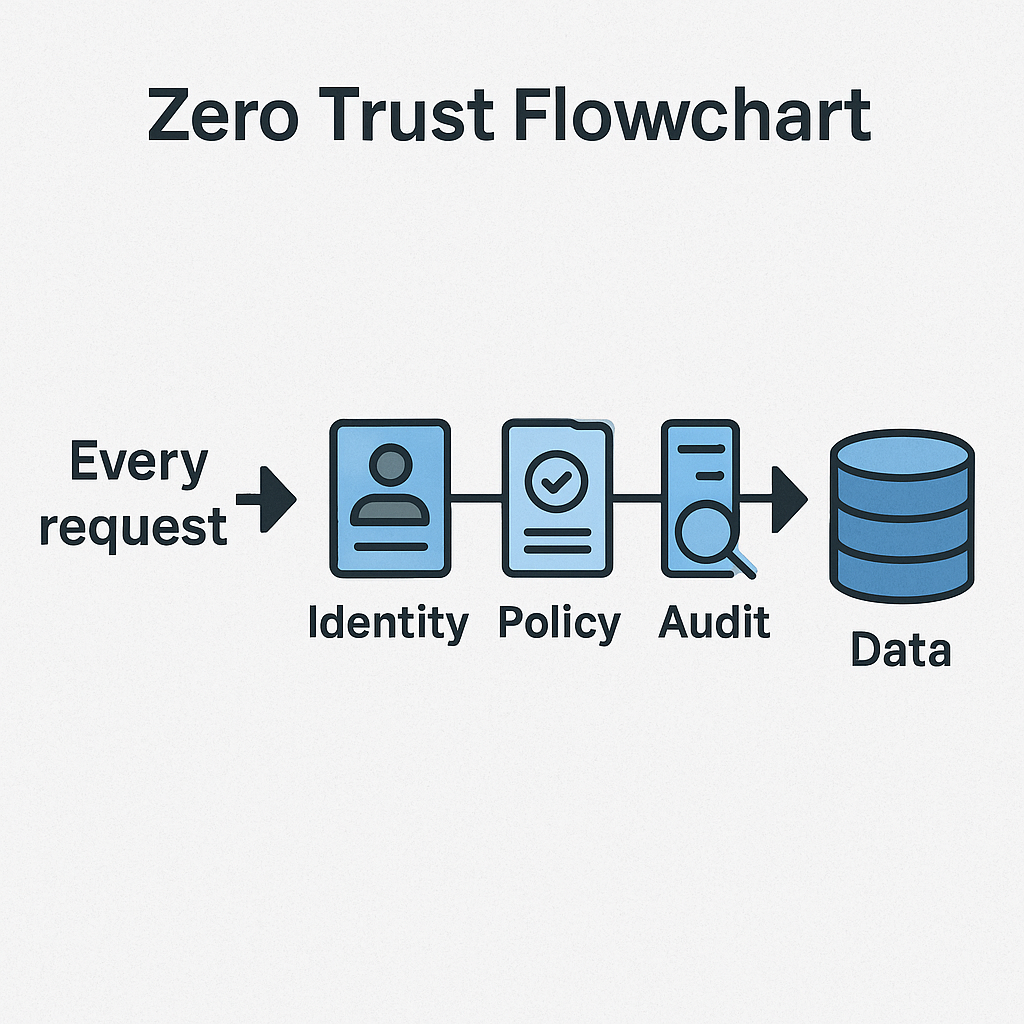
Think of it like giving every employee a keycard that only opens the exact rooms they need—and logging every time they swipe.
This level of control isn’t just about cybersecurity hygiene—it’s mission critical. One exposed data bucket can cost you millions. One rogue insider can derail your operations.
So before we get to the AI magic or multi-cloud utopias, step one is basic: Lock it down. But do it smartly, with the flexibility that today’s environments demand.
2. Accept That the Data Isn’t Moving (And That’s Okay)
Here’s a hard truth: You’re not going to centralize everything.
Sure, the dream of the “single source of truth” lives on in pitch decks, but in real life, data lives everywhere—and that’s not going to change. Between cloud providers, SaaS platforms, partner networks, and on-prem systems, most enterprises are juggling dozens of systems.
Instead of trying to drag everything into one mega data lake (good luck with that), the better approach is to connect to where the data already lives.
That means:
- Using APIs, data virtualization, and smart ETL tools that can reach across systems
- Applying semantic search layers so your teams can find what they need without knowing where it is
- Building federated query systems that respect the security rules of the underlying source while still surfacing relevant insights
This is what makes your enterprise data discoverable—without compromising control.
AI doesn’t need your data in one place. It just needs to know how to get to it. So stop herding cats and start building smarter fences.
3. Make the Data AI-Ready from the Start
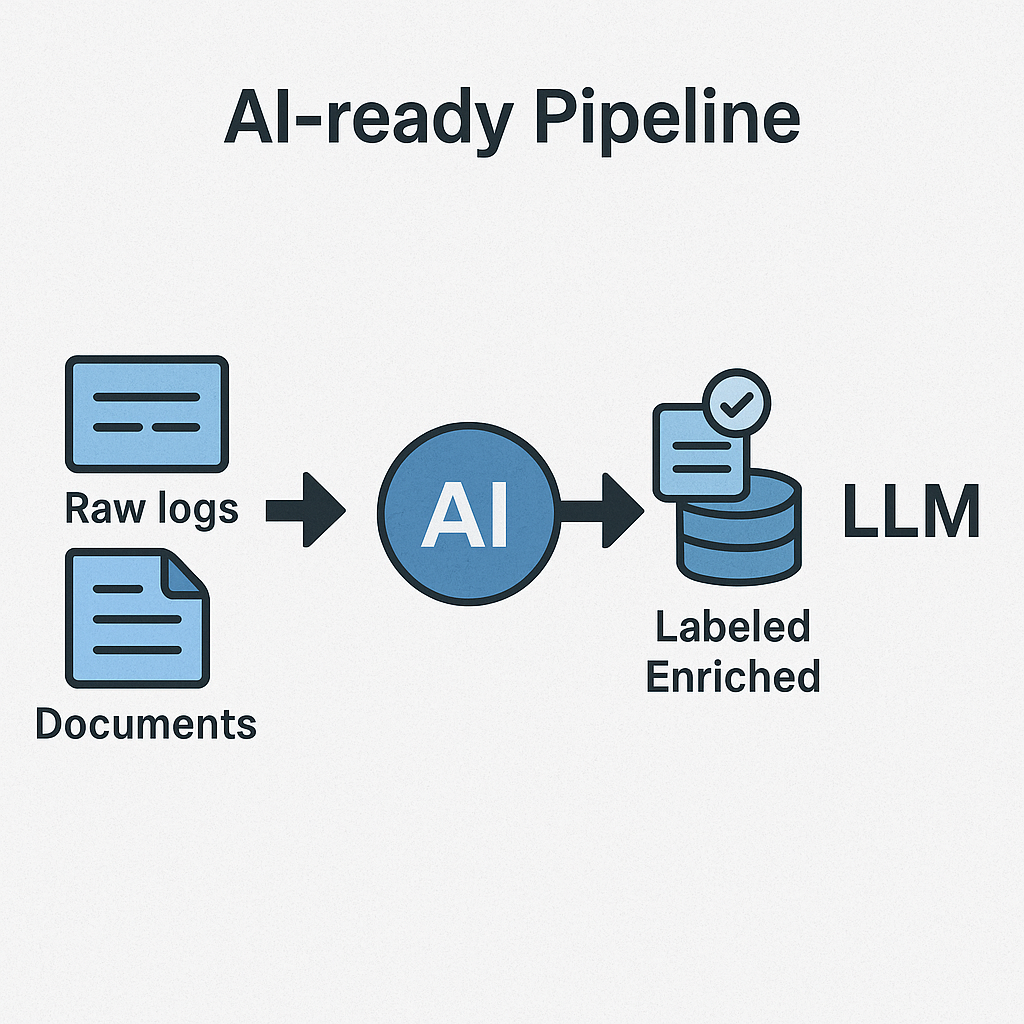
Here’s the thing about AI: it’s only as smart as the data you feed it.
If your files are full of duplicates, your logs are missing context, and your database fields are named “thing1” and “thing2”—your fancy LLM is going to give you fancy garbage.
To make your data truly AI-ready, you need to:
- Tag it with context: Who owns it? What’s in it? What does it relate to?
- Clean it automatically with tools that normalize, deduplicate, and structure unstructured chaos
- Track lineage so you know where the data came from and whether you can trust it
And yes, this is where agentic AI can start to shine.
Smart agents can now crawl through unstructured data—emails, PDFs, reports, logs—and extract structure on the fly. Think: automatic summarization, relationship mapping, tagging, and even classification into your data taxonomy.
It’s like having a team of interns who don’t sleep, don’t make mistakes, and never ask for coffee.
And the payoff? You get usable data in real time, without an army of analysts.
4. Build Your Stack Like a Platform, Not a Patchwork
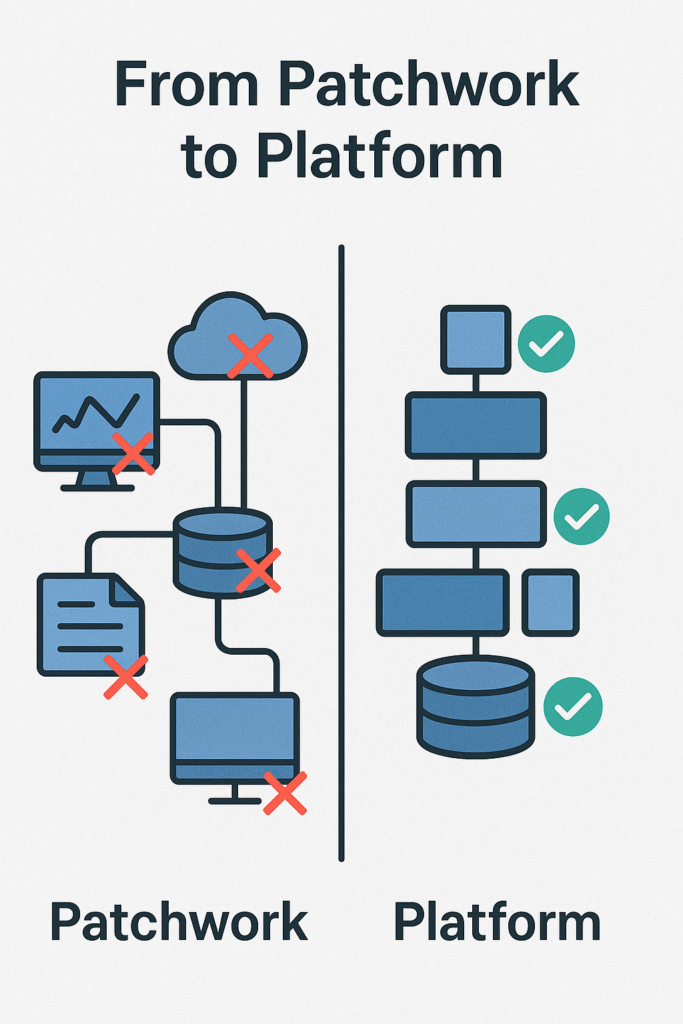
Here’s a fun game: ask a CIO to draw their current data architecture on a whiteboard.
What you’ll usually get is… chaos. A spaghetti chart of tools duct-taped together: A data warehouse here, an observability platform there, fifteen “temporary” scripts running nightly, and three cloud dashboards with slightly different numbers.
It’s not sustainable.
What modern data wrangling demands is platform thinking.
That means:
- Centralized policy enforcement — so governance isn’t a game of telephone across tools
- Observability from end to end — from ingestion to AI inference
- Modular architecture — so you can evolve without breaking everything
- Edge-to-core orchestration — because your insights shouldn’t stop where your cloud does
This is how you get from “we have data” to “we have leverage.”
5. Design for Decision Speed, Not Just Storage
Ultimately, this isn’t just about storing or moving data. It’s about making decisions—faster, smarter, and more confidently.
That might mean:
- Feeding AI assistants for analysts, support agents, or medical teams
- Powering dashboards that update in real-time for operations
- Triggering automations based on events or anomalies
In a mission-critical environment—defense, healthcare, cybersecurity—seconds matter. If your data architecture can’t move at the speed of your mission, it’s not good enough.
Wrangling data isn’t just about control. It’s about clarity. Velocity. Trust.
Final Thought: You Don’t Need a Data Lake. You Need a Data Strategy.
Let’s be honest—wrangling enterprise data isn’t sexy. It doesn’t get applause in the boardroom or trend on LinkedIn. But it is what makes AI possible, security achievable, and insights operational.
And the teams that get this right? They don’t just survive the data deluge. They use it to outpace, outthink, and outperform.
Ready to wrangle?
Colossal helps federal and enterprise organizations build secure, intelligent data architectures that power AI, observability, and zero trust from the edge to the cloud.











